Merging Languages
Merging without analysing languages
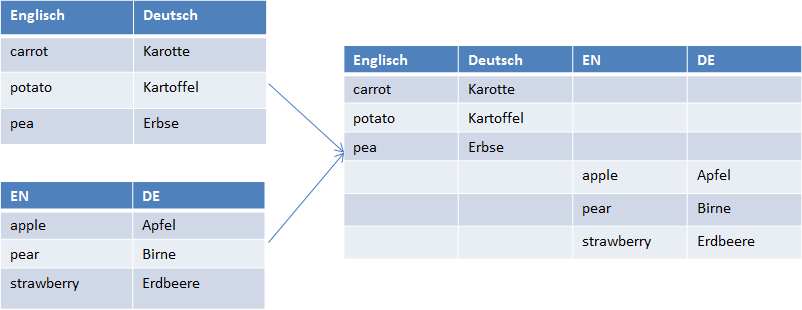
When merging multiple files, column names are used for synchronisation by default. That is, each different column name will result in a new language. See below: 4 column labels result in 4 merged languages.
Exact Merging
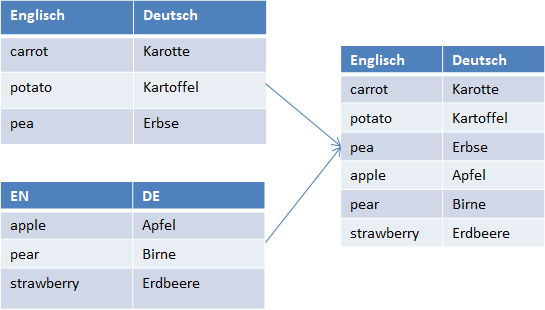
In the example, you actually have only 2 languages, they just happen to have different labels. If you select language merging, any exactly identical languages will be combined into one. Identity is checked by the languages that are assigned to the fields in the settings, be it automatically or in the settings dialog. The new column will have the name used in the alphabetically first source file. That is, if you merge Old_terms.csv and New_terms.csv, the labels from New_terms.csv are used.
Merging Sublanguages
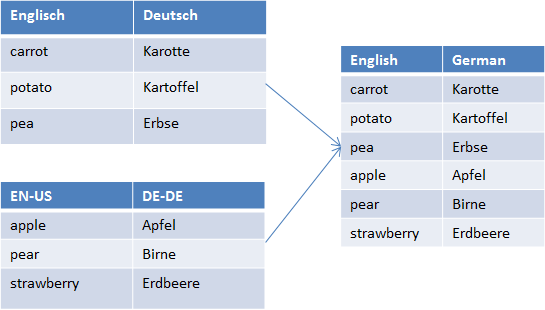
Sometimes you may have termbases in different sublanguages, but you don't care about the flavour. In that case, you can select to merge sublanguages. Any region code will be stripped, and for example both EN-GB and EN-US are reduced to EN. The language name used in the merged file is the English name of the base language, in the example that's English.
Created with the Personal Edition of HelpNDoc: Free EPub and documentation generator